4月2日,由中国科学院中国科学院古脊椎动物与古人类研究所、成都理工大学及英国、美国古生物学家等合作完成的论文“Artificial intelligence in paleontology(古生物学中的人工智能)”发表在地球科学领域综合期刊《地球科学评论》(Earth-Science Reviews)。研究团队全景式地回顾了过去半个世纪人工智能技术在古生物学领域的发展,并且对当下和未来的人工智能古生物学研究作出了展望,这也是领域内首个综述性研究。

图1. 古生物人工智能研究主要事件(橙色)与部分人工智能重要算法与数据集(蓝色)时间线
通过构建具有海量参数的模型与庞大的训练数据集,以深度学习为代表的人工智能技术在过去十余年中得到了高速发展,目前已在多个领域取得了巨大的进步。在科研方面,生命科学和地球科学中的各个子领域开始将人工智能技术用于挖掘、处理、分析数据,例如解析蛋白质结构与预报天气,相比“传统”方法或手工操作具有明显优势。作为生命科学与地球科学的交叉学科,古生物学中的人工智能应用较少。
通过梳理1980年代至今的80余项使用人工智能技术的古生物学研究,团队发现大多数研究都采用图像数据作为输入(图2),包括普通光学照片、显微照片、CT扫描图像等等,这无疑得益于计算机视觉的快速发展。现有的古生物研究已经事实上进入“多模态数据”时代,多种形式的图像、图像衍生的标志点与轮廓线、形态学描述、地层数据、同位素、光谱等种类繁多的数据已经被用于古生物研究的各个方面,但是对“非图像”数据中信息的挖掘和多模态数据中信息的汇总,目前工作开展得还非常有限。

图2. 人工智能古生物学研究使用的输入数据类型、算法、任务、生物类群
在算法方面,早期研究以依托规则与数据库的知识系统/专家系统(Knowledge-Based System/Expert System)为主,在90年代后逐渐式微。现有的研究主要使用卷积神经网络(CNN)和其他机器学习算法(例如支持向量机Support Vector Machine与随机森林Random Forest),最近提出的以注意力机制为核心的变换器(transformer)架构使用较少。自2017年起,有研究使用在ImageNet上经过预训练的模型(迁移学习)开展后续工作,这可能代表了古生物学人工智能未来发展的趋势之一。在自身数据稀缺的情况下,借助较为全面的大型数据集进行预训练,甚至使用已经训练好的模型,之后再根据下游任务进行微调,从而节约成本。在主流人工智能研究领域,2012年提出的AlexNet开启了卷积神经网络的热潮,2014提出的生成式对抗网络与2015年提出的扩散模型奠定了生成式人工智能的基础,2017年提出的注意力机制成为了现在几乎所有大语言模型的核心,而2018年至今的各种大语言模型已经在诸多领域达到或者超过人类平均水平。由此看来,古生物人工智能研究在算法上与主流研究还存在着大约10年的差距,在未来几年可以期待多种新技术在古生物领域的落地。
在数据规模上,现有的古生物训练数据集远远不及主流数据集(图3),2019年提出的有孔虫图像数据集Endless Forams 仅仅达到1998年提出的MNIST手写数字数据集的同等量级(~104张图像,约101~102MB),即存在着大约20年的差距。最近出现了一些规模超过MNIST数据集的古生物图像数据集,同时也发表了大量仅仅在数百至数千张图像上进行训练的古生物人工智能研究,这既显示人工智能作为一种技术正在得到更广泛的应用,也暗示日益降低的模型训练和部署成本可能带来了泡沫。2009年发表的ImageNet数据集包含了超过1400万张图像(~107,约1TB),目前尚未出现达到类似规模的古生物图像数据集,而用于训练超大规模参数模型的数据集在容量上往往可以达到数十TB至PB量级。而且现有的古生物训练数据集中大多为图像-分类标签或图像-解剖结构分割标签,对训练用于非图像数据的模型并不友好。
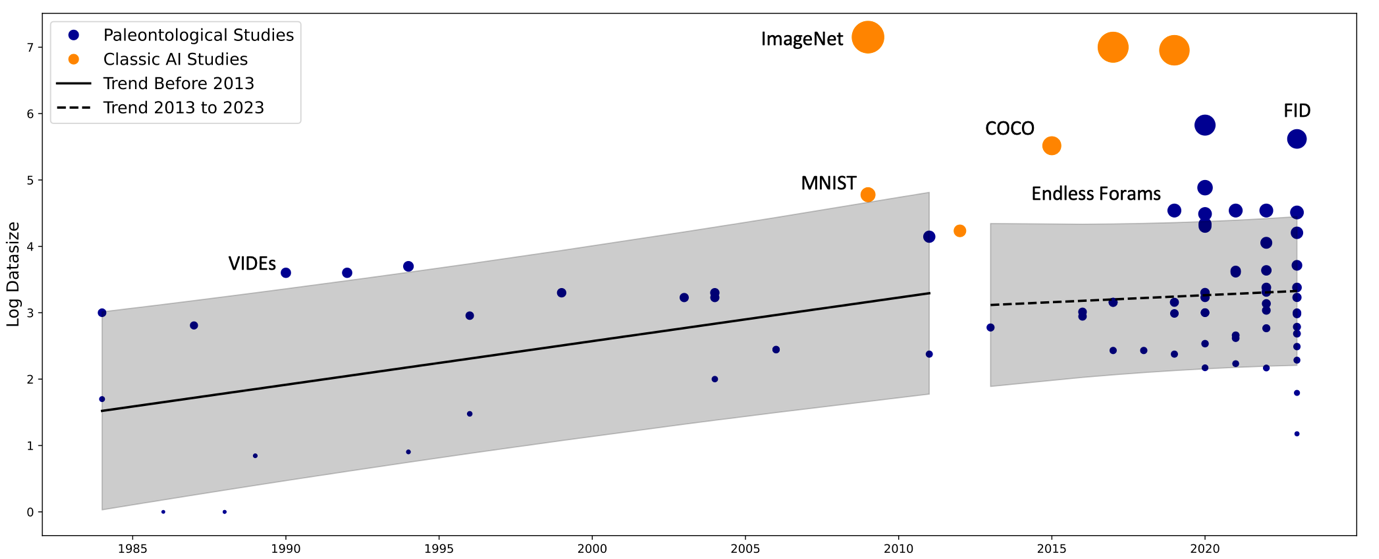
图3. 人工智能古生物学数据集(蓝色)与主流人工智能数据集(橙色)大小对比
古生物人工智能目前主要用于分类任务,另有少数用于图像识别、图像分割、预测等。一方面,分类学或系统发育研究始终是古生物学的核心,将人工智能技术用于分类任务是理所当然的;另一方面,数据集模态与化石数据来源的限制使得分类任务是目前最为可行的古生物学人工智能任务。大约四分之三的化石数据集是针对有孔虫、微体化石、或者无脊椎动物;体型较大的脊椎动物和植物化石数据集目前非常有限。
综上所述,研究人员认为古生物人工智能研究与主流研究在数据集规模上存在大约20年的差距,在算法上存在大约10年的差距,但技术进步有可能在短期内缩短这些差距。
古生物研究的基础是化石标本,大量研究报道了某件或某几件化石标本的形态、系统发育位置、地层学信息、以及其他方面的信息,研究人员将其称为“标本驱动”的古生物研究,它们构成了古生物学的基础。但另一方面,大约100年前出现了对全球马属及其近亲物种宏观演化历史的研究,而20世纪70年代Sepkoski通过手工收集整理化石物种数据,构建了显生宙生物多样性曲线;最近也有大量古生物研究基于较大规模的数据集来研究生物的宏观演化历史或其他方面(图4)。尽管这些研究的基础依然是化石标本,但并不依靠某件或某几件特定的化石标本;研究人员将其称为“数据驱动”的古生物学研究。显然,很难在“标本驱动”与“数据驱动”两种研究之间划出一道泾渭分明的界限,但最近20年随着越来越多基于较大规模的数据集的古生物研究出现,古生物研究的整体范式是更加倾向于“数据驱动”的,也有研究人员将这类研究称为“定量古生物学”研究。这种使用定量化方法、数据驱动的研究模式也是目前生命科学与地球科学中共同的趋势。
最近10年,随着数据量的增加,大量的古生物研究已经逼近手工处理的极限。在传统研究的范式下,可以在样本中继续增加1个、10个、甚至100个新的标本数据,但是无法实现数据在数量级上的提升。因此迫切需要自动化处理古生物学研究中的大量环节,包括但不限于形态学描述、形态学特征编码、几何形态学数据收集、微体化石鉴定、CT图像分割、组织学切片结构识别等等。过去四十余年人工智能在古生物学中的发展已经成功地验证了其可行性,在近期可能会出现更多可以实用的人工智能模型用于工作环节的自动化,由此可以减轻长期以来手工操作中不可避免的巨大时间成本与个人偏见。

图4. 两例“数据驱动”的哺乳动物古生物学研究
最后,研究人员希望通过构建更大规模的训练数据集与移植前沿算法来获得更高效的古生物学人工智能模型。以大语言模型和生成式人工智能为代表的新技术目前尚未用于古生物学研究,但通过其他领域的进展和正在开展的研究,这两项技术将会在极短时间内投入实用(图5)。但同时我们也需要警惕,随着生成式人工智能技术的成熟,化石数据的真伪鉴定可能会面临更加严峻的挑战,如何避免未经检查生成的错误内容需要更严格的监督,在模型训练阶段;在不侵犯版权拥有者权益的前提下收集数据也将是未来古生物人工智能发展的难点。

图5. 两例基于生成式人工智能的恐龙复原图
成都理工大学余琮煜为论文第一与通讯作者,中国科学院古脊椎动物与古人类研究所王海冰、江左其杲、徐星为论文共同作者。中国科学院自动化研究所、南方科技大学、云南大学、沈阳师范大学、美国纽约理工大学、英国布里斯托大学、英国伯明翰大学、瑞典斯德哥尔摩大学、英国自然历史博物馆等国内国际多个单位参与了研究。美国自然历史博物馆古生物部Mark Norell教授与孟津教授对本文亦有贡献。本研究得到国家自然科学基金委,中国科学院青促会,云南省“兴滇英才支持计划”、瑞典研究委员会、成都理工大学“珠峰引才计划”、以及深时数字地球(DDE)国际大科学计划的资助。
原文链接:https://www.sciencedirect.com/science/article/pii/S0012825224000928